人工智能是一种非常耗费内存的应用。幸运的是,Ambiq 的 Apollo4 Plus 有多种内存类型和配置可供选择。决定使用哪种内存以及如何使用可能需要做一些实验。因此,我们进行了一些实验,结果供您参考。正如您在下文中看到的,有很多不错的选择可以帮助满足您的设计要求。
人工智能如何使用内存
深度学习人工智能模型由一系列层组成,每个层由许多所谓的 “神经元 “组成。单独来看,这些神经元非常简单:它们接收一个输入值,然后乘以与该特定神经元相关的 “权重"。具有权重的神经元会对组合应用 “激活函数",然后将其输入到下一层。对于一个训练有素的模型来说,权重是静态的,永远不会改变。
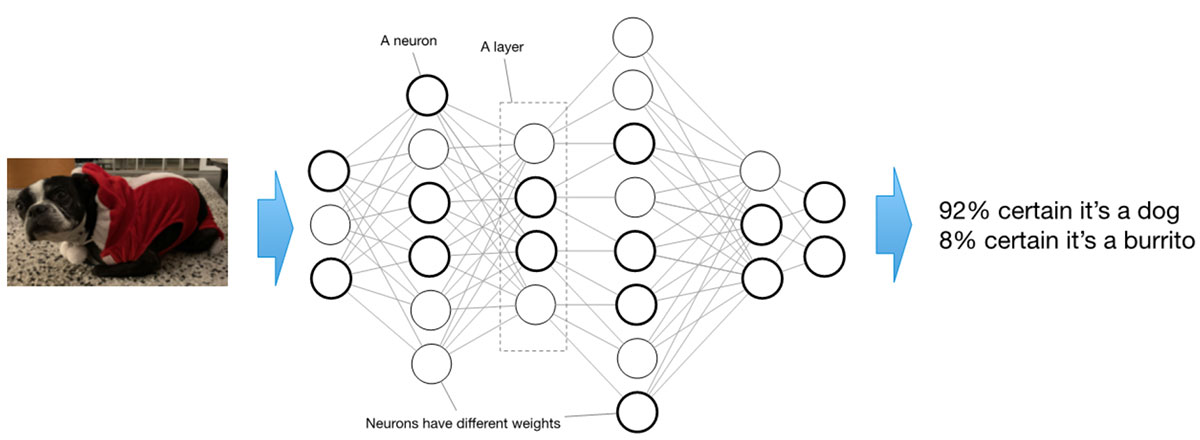
诚然,这种描述过于简单。不过,它确实表明,人工智能模型的内存利用由两部分组成:静态部分和动态部分。静态部分代表权重。动态部分包括根据这些权重流经神经元的值,也称为 “激活"。我们将利用这些事实来探讨如何针对 Apollo4 Plus 的内存配置优化人工智能模型。
用于微控制器的TensorFlow1Lite 是一个运行时解释器,可通过人工智能模型运行数据,每次推理都要执行上述操作数百万次。微控制器的内存架构反映了运行人工智能模型所需的权重和激活内存类型。模型的权重定义为模型各层使用的参数(包括可训练和不可训练的参数),存储在模型数组(用于存储和分析的多个模型对象的集合)中。我们可以使用编译器指令控制编译过程中这些内存对象的位置。例如,我们在 AmbiqSuite SDK 中就是这样控制放置位置的:

阿波罗 4 Plus 回忆
Apollo4 Plus SoC 提供三种可用于人工智能的存储器:MRAM、紧耦合存储器(TCM)和 SSRAM。MRAM 是一种高效的非易失性存储器,主要用于存储静态值。TCM 是一种高性能读/写存储器,顾名思义,与 CPU 紧密耦合。SSRAM 是通用读/写存储器,与 CPU “距离 “较远。访问每种存储器都会产生不同的功耗和性能影响。
实验
众所周知,TensorFlow 的性能很难预测。因此,进行实验是一种更简单的方法。在实验中,我们运行了MLPerf2Tiny Inference 的关键词定位(KWS)基准。我们利用该基准的复杂系统来测量性能和功耗利用率,从而根据经验确定各种内存分配方法的影响。具体来说,我们尝试了以下配置:
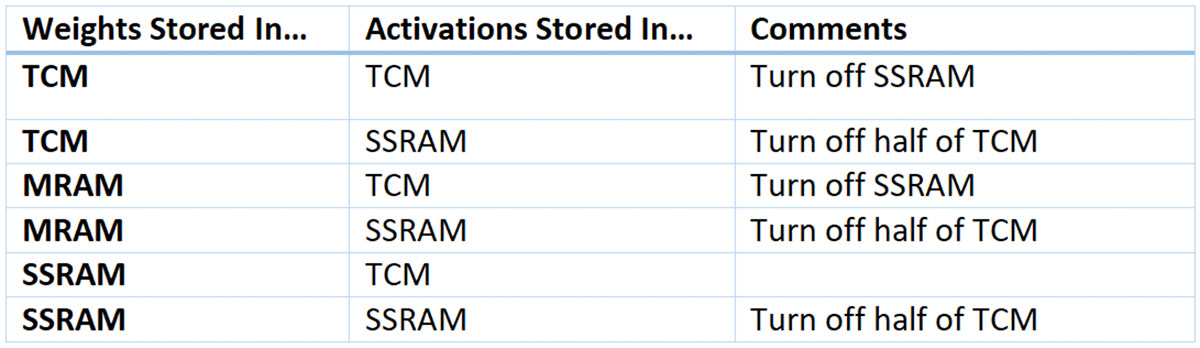
有几个要点需要注意:
- 我们从不在 MRAM 中存储激活,因为激活是动态的,而 MRAM 喜欢保持静态
- 我们关闭所有不使用的内存
结果
下图显示了每个实验的测量结果,相对于我们选择的一切运行在 TCM 中的基线。我们使用坐标轴来夸大实验之间的差异。实际上,这些组合中的任何一个都非常适合在物联网边缘设备上运行关键词搜索。
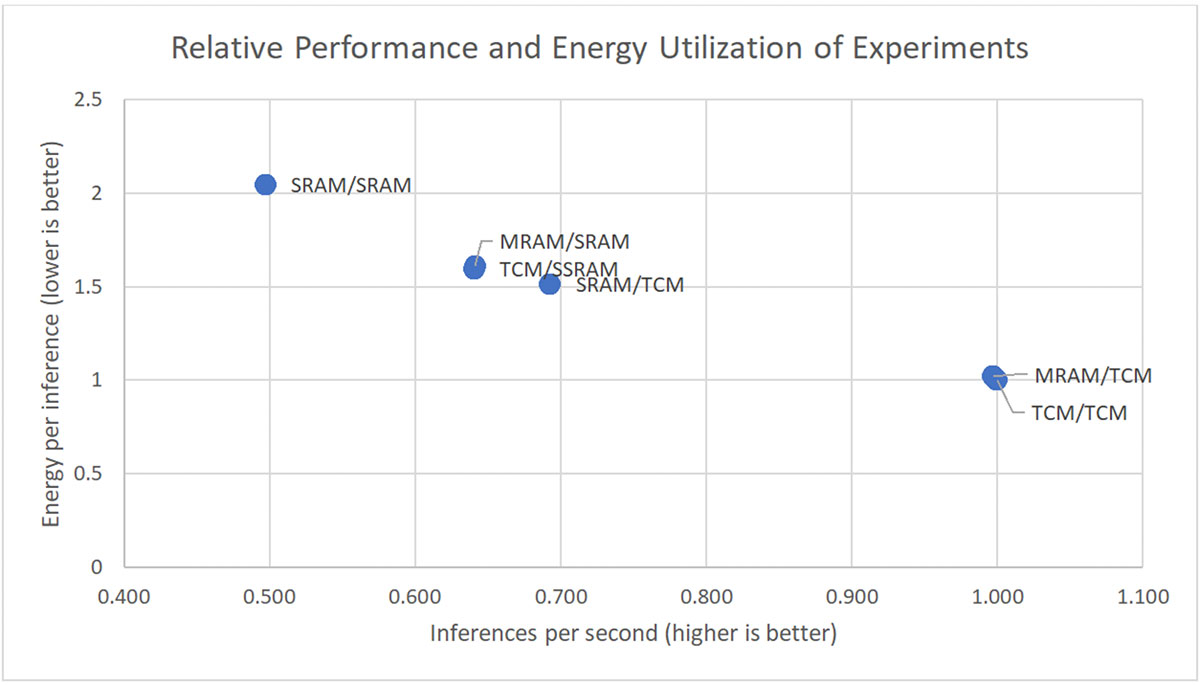
我们可以看到,当与 TCM 或 SSRAM 配合使用时,MRAM 可提供出色的性能和能效。
结论
人工智能需要大量内存,包括静态和动态内存。但在实际应用中,人工智能必须与其他应用共享内存。Apollo4 Plus 在内存类型和内存配置方面为人工智能开发人员提供了许多选择。在上述体验中,开发人员如果希望提供最优化的性能和能效,可以将权重放在 Apollo4 容量为 2MB 的 MRAM 中,而将激活放在 TCM 中,这样几乎不会产生影响。不过,无论开发人员选择何种配置,我们支持 SPOT 的平台3都将始终如一地可靠提供卓越的性能和出色的能效。
1TensorFlow、TensorFlow 徽标和任何相关标志均为谷歌公司的商标。
2MLPerf 是一个由来自学术界、研究实验室和产业界的人工智能领军人物组成的联盟,其使命是 “建立公平、有用的基准",为硬件、软件和服务的训练和推理性能提供无偏见的评估–所有评估均在规定的条件下进行。 https://mlcommons.org/en/policies/。
3 SPOT®(阈下功率优化技术)是 Ambiq® 的专有技术平台。它通过提供市场上全球最节能的解决方案,彻底改变了边缘人工智能的可能性。

