前回のブログでは、言語を使ってあなたの発言を理解するAIモデルと、あなたの発言の「要点」を理解するモデルの違いを紹介しました。今日の記事では、後者について掘り下げます。
「OK、コンピューター
今日、私たちは音声AIとの対話の主流であるトリガー・フレーズに慣れ親しんでいる。「Hey Siri」や「Hey Alexa」は私たちの日常生活の一部となっている。
このアプローチを考え出した人々は、2つの問題を解決しようとしていた。1つ目は、ユーザーがいつAIに話しかけているのかを判断する明確な方法が必要だったこと、2つ目は、AIが常にレスポンスよく、しかし効率的にコマンドを聞く必要があったことだ。「OK、コンピューター」は自然言語のパターンではないが、AIを使って実装するのは簡単だ。理想的には、賢い人間のアシスタントに話しかけるようにAIに話しかけることができ、私たちが明確に名前を言ったときだけでなく、文脈に基づいて私たちがいつ話しているのかがわかるようにAIを信頼することだ。キーワードトリガーは、AIとパワーの制限を回避するために作られたものだが、もはやそれほどの意味はない。
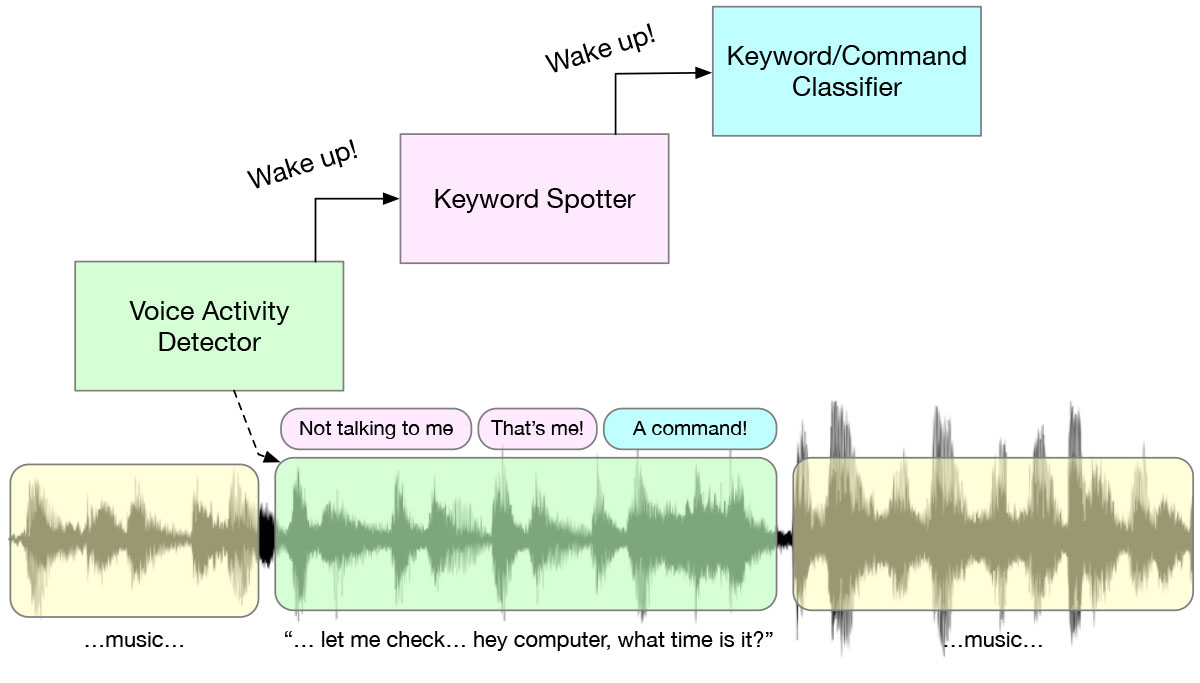
キーワードを発したときに舞台裏で起こるのは、興味深い多段階ウェイクアップ・システムであり、電力を節約するために設計されたアルゴリズムとAIモデルのカスケードである。常に耳を傾けているボイス・アクティビティ・ディテクター(VAD)から始まり、発話があるとKWSモデルがトリガーされ、その発話が “Hey Alexa “のような事前に定義されたキーワードかどうかを検出する。これがすべて行われた後に初めて、より複雑な処理が行われる。このカスケードは、電力効率のために設けられています。各段階で、可能な限り負荷の少ないアルゴリズムを実行します。
“ハンマーしかないときは…"
キーワード検出のためのニューラルネットワーク・アプローチは数多くあるが、(少なくとも私にとって)最も興味深いものは、スペクトログラフィック・シグネチャーの認識に基づくものだ。スペクトログラムは音声を周波数領域に変換した画像であり、AIは画像を分類するのが得意だ。猫を認識するAI画像分類モデルをトレーニングするには、猫の写真をたくさん見せる必要がある。キーワード・スポッターのトレーニングも概念的には同じで、人々がそのフレーズを言う何千もの例を記録し、それぞれのスペクトログラム(基本的には画像)を計算し、それらの画像を認識するようにモデルを訓練する。
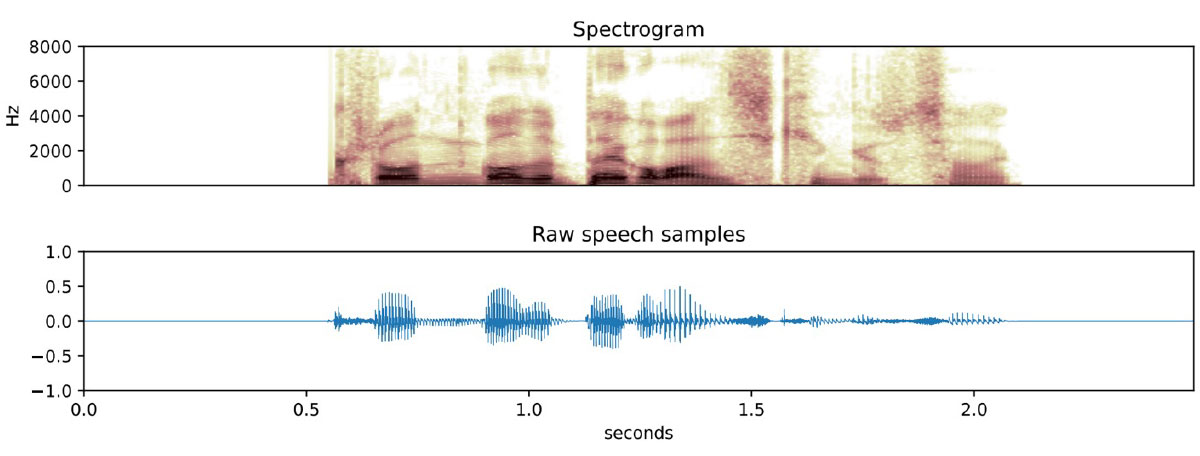
このアプローチには限界があり、最も重要なのは、オーディオがあまり長くないことです。スペクトログラムは、一定時間の音声の断片の周波数をとらえるもので、時間が長すぎると反応と精度が落ちる。つまり、このアプローチは2~5秒のフレ��ズには適していますが、長い文章を必要とするタスクには適していません。
画像分類は最も古く、最もよく理解されているAIタスクの1つであるため、このクラスのアルゴリズムを活用することは理にかなっている。画像分類の多くの特徴は、オーディオにも当てはまります。最も有益なのは、ニューラルネットワークが「パターンマッチング」を「マッチングされるパターン」とは別に学習するように設計できることだ。これは実用的な意味では、ゼロから始めるのではなく、転移学習を使ってAIに新しいフレーズを教えることを意味する。
“私が言うことではなく、私が言いたいことをする"
音声を画像として扱い始めると、単純なウェイクワード以上のことができるようにAIを訓練できることがわかった。次の論理的なステップは、多くのコマンドワードでモデルを訓練することである。このモデルは、カーナビゲーションシステムをオンにするために「ナビゲーション」と言うときのように、簡単なユーザーインターフェースを作成するために使用できる。
実際には、単純な命令以上のことができる。発話されたフレーズから話者の意図を推測するモデルもある。このようなSpeech-to-Intentモデルは、数十のフレーズの何千ものバリエーションで訓練されており、これまでに聞いたことのないバリエーションに汎化することができる。このようなモデルは、音声ベースのユーザー・インターフェースを作成するのに非常に有用であり、最終的にデバイスが通常のフィックス・フレーズ・インターフェースから解放されることを可能にする。
実務上の問題
Apollo4は、超低消費電力、192Mhzのパフォーマンス、超効率的なオーディオ・ペリフェラル、2MBのMRAM、余裕のあるキャッシュ、大容量の密結合メモリを備えており、KWSやSpeech-to-intentなどのAIモデルの実行に非常に適しています。モデルのサイズはキーワードやインテントの数によって異なりますが、一般的に200KB以下のRAMに収まり、推論あたり500uJ程度です。推論の待ち時間は、フレーズ長以下であれば全く問題なく、例えばKWSでは約50ミリ秒かかります。
ディープ・ランゲージ・モデルに基づく音声認識はまだ先だが、アルゴリズムとデバイスの両面で着実な進歩が見られ、来年か再来年には実用化されるだろう。
聖杯
上で書いたように、ほとんどのAIベースの音声ユーザー・インターフェースは不便で、ユーザーのニーズよりもエンジニアリングの制約に基づいて設計されているため、アレクサやシリのユーザーは「タイマーをスタート」や「音量を上げる」といった使い古された単純なコマンドに固執することになる。
あなたのデバイスは、あなたが時計に話しかけているのか、それとも実際の人間に話しかけているのか、あらゆる種類の文脈情報に基づいて知るようになり、いくつかの重要なフレーズを覚えることを要求する代わりに、優れたパーソナル・アシスタントがそうであるように、あなたの意図を読み取ることを学習するようになるだろう。

