我們的上一篇部落格文章 介紹了使用語言來理解您所說內容的人工智慧模型和了解您語音「要點」的模型之間的區別。在今天的帖子中,我們將深入探討後者。
“好的,電腦”
如今,我們都熟悉與語音 AI 互動的主要方式:觸發短語。「嘿 Siri」和「嘿 Alexa」已經成為我們日常生活的一部分。
提出這種方法的人試圖解決兩個問題:首先,他們需要一種明確的方法來確定用戶何時正在與 AI 交談,其次,他們需要 AI 始終以響應式但高效的方式監聽命令,這需要大量的 AI 馬力。「OK,電腦」不是自然語言模式,但使用AI很容易實現;理想情況下,我們應該能夠像與聰明的人類助手一樣與人工智慧交談,相信他們會根據上下文知道我們何時說話,而不僅僅是當我們明確說出他們的名字時。創建關鍵字觸發器是為了繞過不再相關的人工智慧和權力限制。
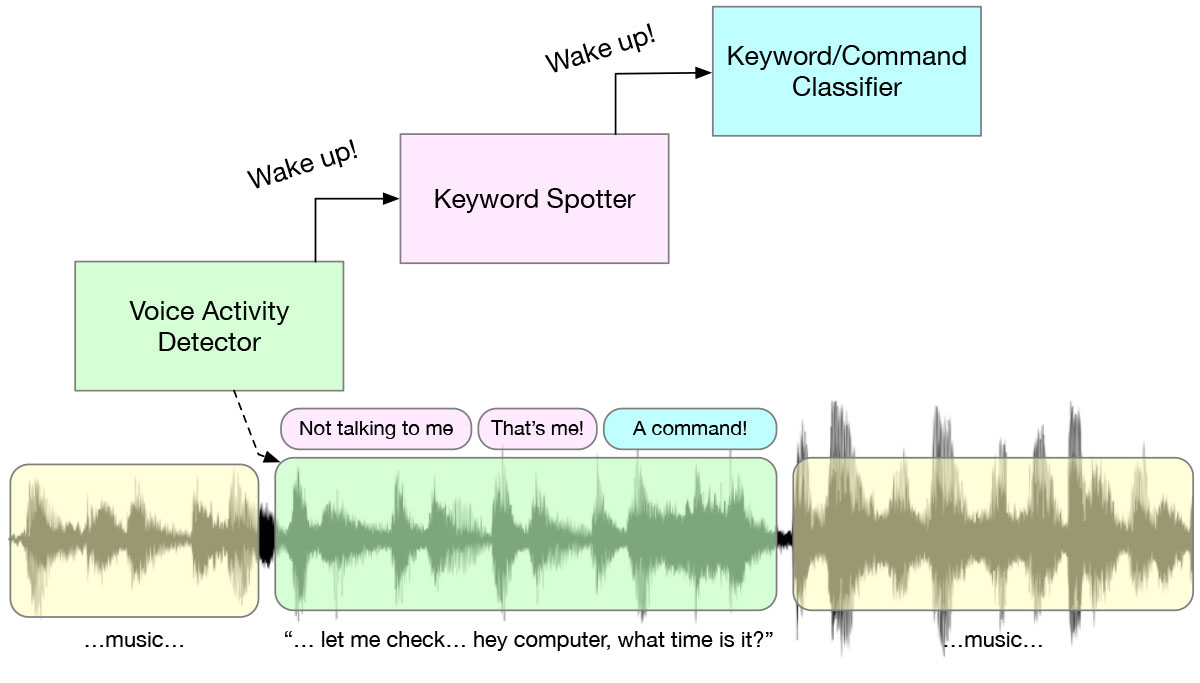
當你說一個關鍵字時,幕後會發生什麼,是一個有趣的多階段喚醒系統,是一系列旨在節省電力的演算法和人工智慧模型。從始終監聽的語音活動檢測器 (VAD) 開始,當存在任何語音時觸發 KWS 模型,並檢測該語音是否是預定義的關鍵詞組,例如“嘿 Alexa”。只有在這一切發生之後,才會發生更複雜的處理。這種級聯是為了提高電源效率而製定的 – 在每個階段,您都會執行要求最低的演算法。
“當你只有一把錘子時……”
有許多用於關鍵字發現的神經網絡方法,但(至少對我來說)最有趣的方法是基於識別光譜特徵。頻譜圖是將音訊翻譯成頻域的圖片,人工智慧非常擅長對圖片進行分類。訓練人工智慧影像分類模型來識別貓需要顯示大量貓的圖片。訓練關鍵字觀察器在概念上是相同的:記錄數千個人們說該短語的範例,計算每個範例的頻譜圖(基本上是圖像),並訓練模型識別這些圖像。
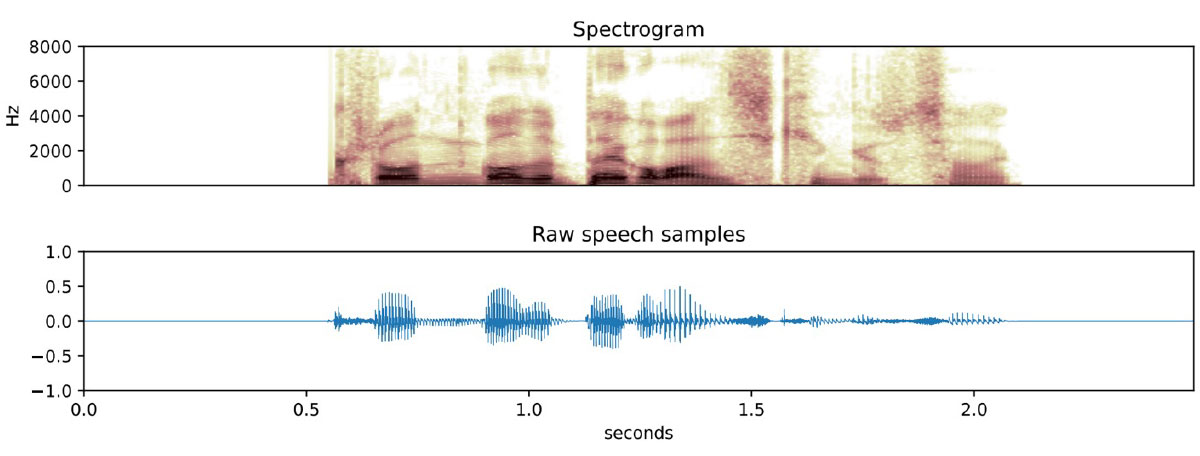
這種方法有局限性,最重要的是音頻不能很長。頻譜圖會擷取一組固定時間內音訊片段的頻率 – 使時間過長,反應能力和準確性會下降。這意味著這種方法適用於兩到五秒的短語,但不適用於需要較長句子的任務。
圖像分類是最古老、最容易理解的人工智能任務之一,因此利用此類算法是有意義的。影像分類的許多特徵也轉化為音訊。最有用的是,神經網路可以設計為將「模式匹配」與「被匹配的模式」分開學習,這實際上意味著使用遷移學習來教人工智慧一個新短語,而不是從頭開始。
“做我的意思,而不是我說的”
事實證明,一旦您開始將音訊視為圖像,您就可以訓練您的人工智慧做的不僅僅是簡單的喚醒詞。下一個合乎邏輯的步驟是在許多命令字上訓練模型,這些命令字可用於建立簡單的使用者介面,例如當您說「導航」來開啟汽車的導航系統時。
事實上,我們可以做的不僅僅是簡單的命令。有些模型從口語短語中推斷出說話者的 意圖 。這些語音轉意圖模型經過數十個短語的數千種變體的訓練,並且可以推廣到以前從未聽過的變體。這些模型對於創建基於語音的使用者介面非常有用,最終允許設備擺脫通常的固定措辭介面。
實際事項
Apollo4 具有超低功耗、192Mhz 性能、超高效音頻外圍設備、2MB MRAM、大緩存和大緊密耦合內存,非常適合運行 KWS 和語音轉意圖等 AI 模型。模型大小因關鍵字或意圖的數量而異,但通常適合低於 200KB 的 RAM,每次推理的 sip 約為 500 uJ。推理延遲根本不是一個因素,遠低於短語長度 – 例如,KWS 大約需要 50 毫秒。
基於深度語言模型的語音識別還很遙遠,儘管算法和設備方面的穩步進展將在未來一兩年內實現這一目標。
聖杯
正如我們上面所寫,大多數基於人工智慧的語音使用者介面都很笨拙,是圍繞工程限制而不是使用者需求而設計的,導致 Alexa 或 Siri 用戶堅持使用陳舊的簡單命令,例如「啟動計時器」和「提高音量」。
總有一天,與手錶交談與與人交談幾乎沒有什麼不同:您的設備會根據各種上下文信息知道,無論您是在與它交談還是與真人交談,並且不會要求您記住一些關鍵短語,它將學習閱讀您的意圖, 就像一個好的私人助理一樣。

